北京大学与字节跳动团队近日发布新型强化学习方法 BranchGRPO,通过「树形分叉 + 剪枝」创新机制,将扩散模型对齐训练效率提升近 5 倍,同时突破生成质量与稳定性瓶颈。该成果已被《51CTO》《机器之心》评为「2025 年最具潜力 AI 突破」,核心代码同步开源。

扩散模型凭借高保真、多样性优势,已主导图像合成、视频生成等视觉生成领域,但与人类偏好的对齐优化长期面临两大核心难题:
这一矛盾在视频生成等复杂任务中更为突出 —— 传统方法生成的内容常出现闪烁、变形,且训练效率低下,迭代一次需近 20 分钟。
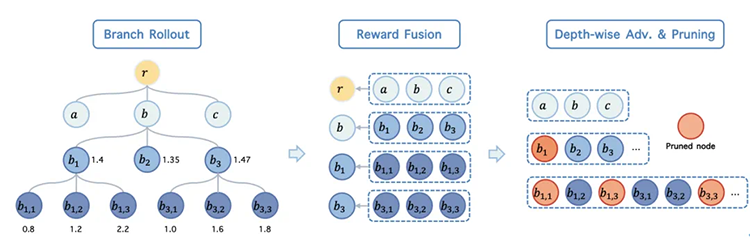
由北京大学仉尚航团队与字节跳动联合研发的 BranchGRPO,通过重构采样流程实现效率与稳定性的统一:
在预设扩散步骤(如第 10、20 步)触发轨迹分裂,多子路径共享前缀计算。例如第 10 步分裂 3 条路径时,仅需 1 次前 10 步计算,后续并行探索不同生成方向。这一设计将计算复杂度从 O (N×T) 降至 O (N+B×T)(B 为分支因子),大幅减少重复采样开销。
颠覆 "终末单奖励" 模式,将叶子节点的质量评分自底向上传递,在每一步生成标准化优势信号。通过深度加权优势估计,模型可精准识别各步骤对最终结果的贡献,解决奖励分配不准确问题,ImageReward 指标达 1.319,刷新全表最佳纪录。
采用 "宽度 + 深度" 双重剪枝策略:宽度上仅保留 2 条最优路径参与反向传播,深度上跳过非关键层的反向计算(保留前向评估)。剪枝版模型迭代时间从传统方法的 698 秒压缩至 314 秒,效率提升超 50%。
迭代效率:从 20 分钟 / 次降至 8 分钟 / 次,提速 2.5 倍;
生成质量:帧清晰度 PSNR 提升 1.2dB,SSIM 提升 0.03,彻底解决画面闪烁、角色动作不连贯问题;
多样性保持:MMD² 距离维持在 0.019,与顺序采样几乎一致,未因加速牺牲生成丰富度。
关键对比:同类加速方案 MixGRPO 虽能将迭代时间压缩至 289 秒,但对齐分数下降且训练频繁崩溃;而 BranchGRPO-Mix 在 148 秒极速下仍保持稳定性能,展现出 "快且稳" 的核心优势。
目前,BranchGRPO 核心代码已开源至 GitHub,支持 PyTorch 与 xFormers 加速库,包含 HPDv2.1 和 WanX-1.3B 的完整训练脚本。其技术突破正推动生成 AI 行业发生三大变革:
降本增效门槛:将大规模对齐训练成本降至传统方法的 1/5,使中小团队无需巨额算力即可开展高质量生成模型优化;
多模态拓展加速:已适配文本 - 图像、视频生成任务,未来计划融合 CLIP、DINOv2 等模型提升语义对齐精度;
技术范式革新:推动 "结构化强化学习" 成为生成 AI 优化新方向,为 3D 内容创作、影视特效等工业场景提供高效框架。





