上海交通大学与上海人工智能实验室联合团队提出的 MM-HELIX 框架,通过引入长链反思机制,显著提升多模态大模型在复杂推理任务中的性能。
该框架包含以下核心模块:
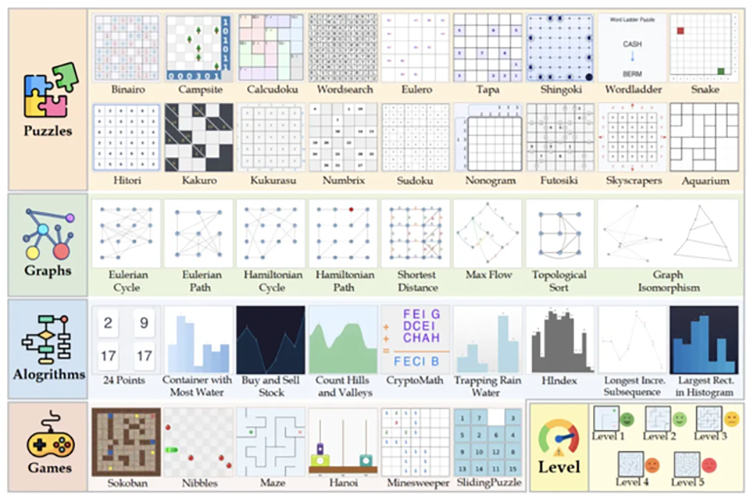
MM-HELIX 基准测试构建了包含 42 类跨领域任务的 “终极考场”,覆盖算法设计、图论分析、策略博弈等高难度场景。例如:
MM-HELIX-100K 数据集采用 “步骤启发式响应生成” 技术,将完整解题过程拆解为关键步骤引导模型生成。相比直接解题模式,推理时间减少 90%,同时有效控制冗余输出。10 万个高质量样本构成的 “反思训练集”,为模型提供了包含自我纠错过程的学习素材。
自适应混合策略优化算法(AHPO)提出动态教学机制:
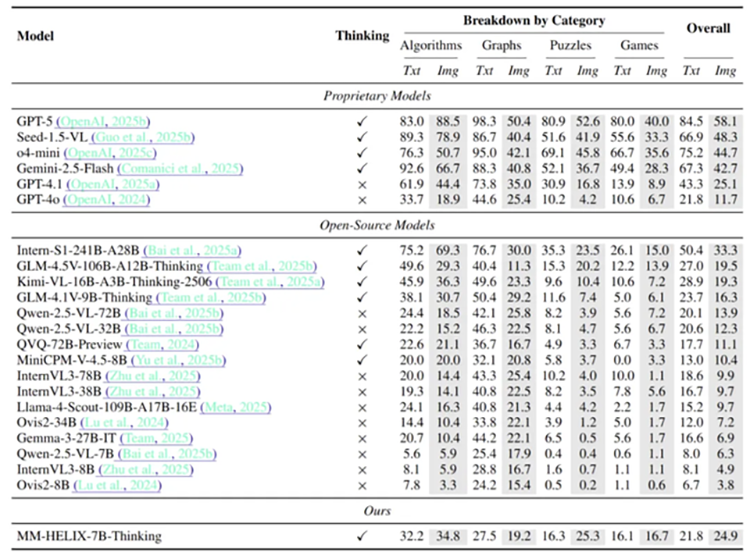
基准测试突破:搭载 MM-HELIX 框架的 Qwen2.5-VL-7B 模型准确率提升 18.6%,超越多个参数量更大的主流模型。
通用推理提升:在通用数学和逻辑推理任务中,平均性能提升 5.7%,表明反思能力具备可迁移的元能力。
开源资源:MM-HELIX 基准测试、数据集及 Sandbox 环境已全面开源,项目主页(https://mm-helix.github.io/)提供技术细节、数据生成流程及算法代码。
当前多模态大模型普遍存在 “一步到位” 的思维局限,难以应对需要试错调整的复杂问题。MM-HELIX 框架首次为 AI 注入人类特有的长链反思能力,通过 “评估 - 训练 - 优化” 闭环,推动模型从 “知识容器” 向 “问题解决者” 转型。其开源工具链为全球研究者提供了突破 AI 决策瓶颈的新路径,尤其在医疗诊断、工业设计等需要深度推理的领域具有重要应用潜力。




